滚球app(中国)官网 英伟达掀桌, Windows 终于迎来真 AI PC


Windows PC 阵营,如故很久莫得遭受真确有重量的闯入者了。

Windows 用户 belike
夙昔四十年,这个市集的基本单干相对谨慎:微软界说操作系统和软件进口,Intel 与 AMD 恒久把守 x86 处理器平台,英伟达则从图形诡计开赴,其后又把 AI 加快推到更高的位置。

而就在黄仁勋刚刚已矣的 2026 年 COMPUTEX 主题演讲上,英伟达沿着 AI 基础设施这条干线,干涉更多产业的中枢门径。
除了 GPU 、AI 工场、物理 AI 等须生常态的话题,还有被微软和 ARM 提前预热、打着「A new era of PC」旗子的 RTX Spark。悉数家具背后,皆围绕吞并个弱点词伸开:
Agent、Agent,如故 Agent。
联手微软,英伟达要重新界说个东谈主 PC
在 Agent(智能体)叙事里,PC 被放到了一个新位置。
四十年来,Windows、通达 BIOS、芯片组、驱动、多媒体 API 悉数塑造了个东谈主诡计。Windows 95 让 PC 从企业开发形成糜掷电子家具,险些每个东谈主皆需要一台电脑。

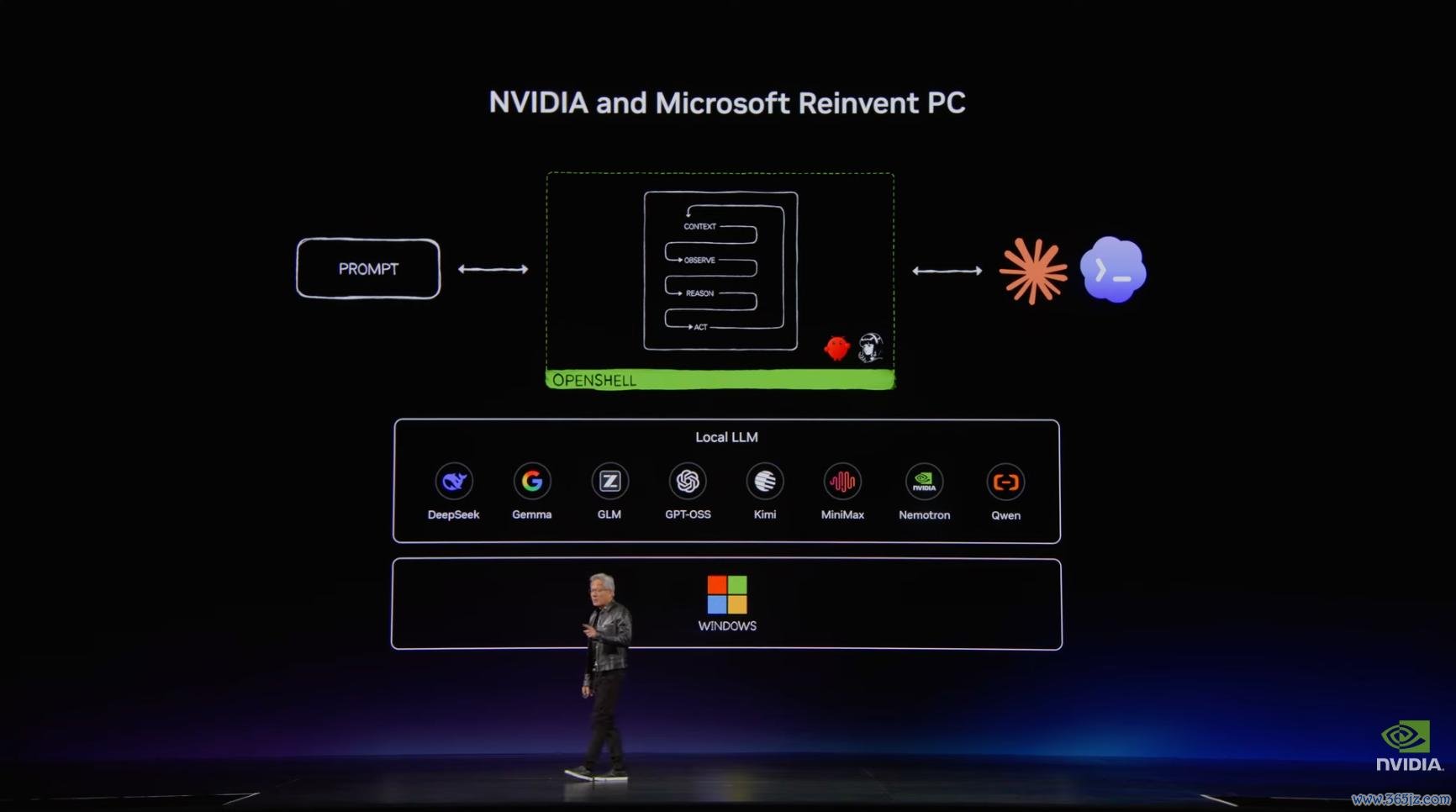
刻下,微软和英伟达将重新界说 AI PC ,见解是要让 PC 原生脱手智能体,让个东谈主电脑从传统应用进口形成个东谈主 AI 平台。
今天推出的英伟达 RTX Spark 处理器是这套新 PC 体系的中枢。

它搭载 Blackwell RTX GPU,FP4 AI 性能达到 1 petaflop;CPU 部分是与联发科配合定制的 20 核 Grace CPU;内存为 128 GB 融合内存,并通过 NVLink C2C 提供 600 GB/s 带宽。软件层面,完好栈包括 CUDA、TensorRT、NVFP4、RTX Ray Tracing、DLSS、Reflex 和 G-SYNC。

在家具口头上,英伟达把 RTX Spark 放进了更接近主流 Windows PC 的尺寸里:
条记本厚度可作念到 14 毫米,重量约 3 磅,掩饰 14 英寸到 16 英寸机型;机身遴荐精密加工铝合金,屏幕部分则配备色调准确的 tandem OLED,并支抓 NVIDIA G-SYNC,既服务创意使命,也兼顾游戏和高帧率视觉体验。
换言之,RTX Spark 面向的场景不仅仅端侧语音助手或轻量办公场景,它试图把部分数据中心 AI 才气、游戏图形才气和专科创作才气,放进个东谈主电脑口头里。

黄仁勋说,这台电脑要脱手「悉数东西」。传统 Windows 应用要能跑,CUDA 软件栈要能跑,图形使命流、数字生物、地震处理、天体物理、基因组学和 AI 应用也要连接脱手,它既不错贯串土产货模子,也不错贯串云表模子。
在现场演示视频中,用户给出场面、草图、立场参考和需求后,脱手在 RTX Spark 上的智能体会调用 Rhino 完成建筑与室内决策想象,并导入 Blender 合资 Flux 2 生成多角度渲染图,过程顶用户可随时修改。
演示传递的信号可想而知,PC 将从东谈主手动操作软件转向智能体围绕见解调遣器用,而典型案例是,Adobe Photoshop、Premiere 等应用也正为 RTX Spark 优化,并通过 MCP 接入土产货智能体,成为自动化使命流的一部分。
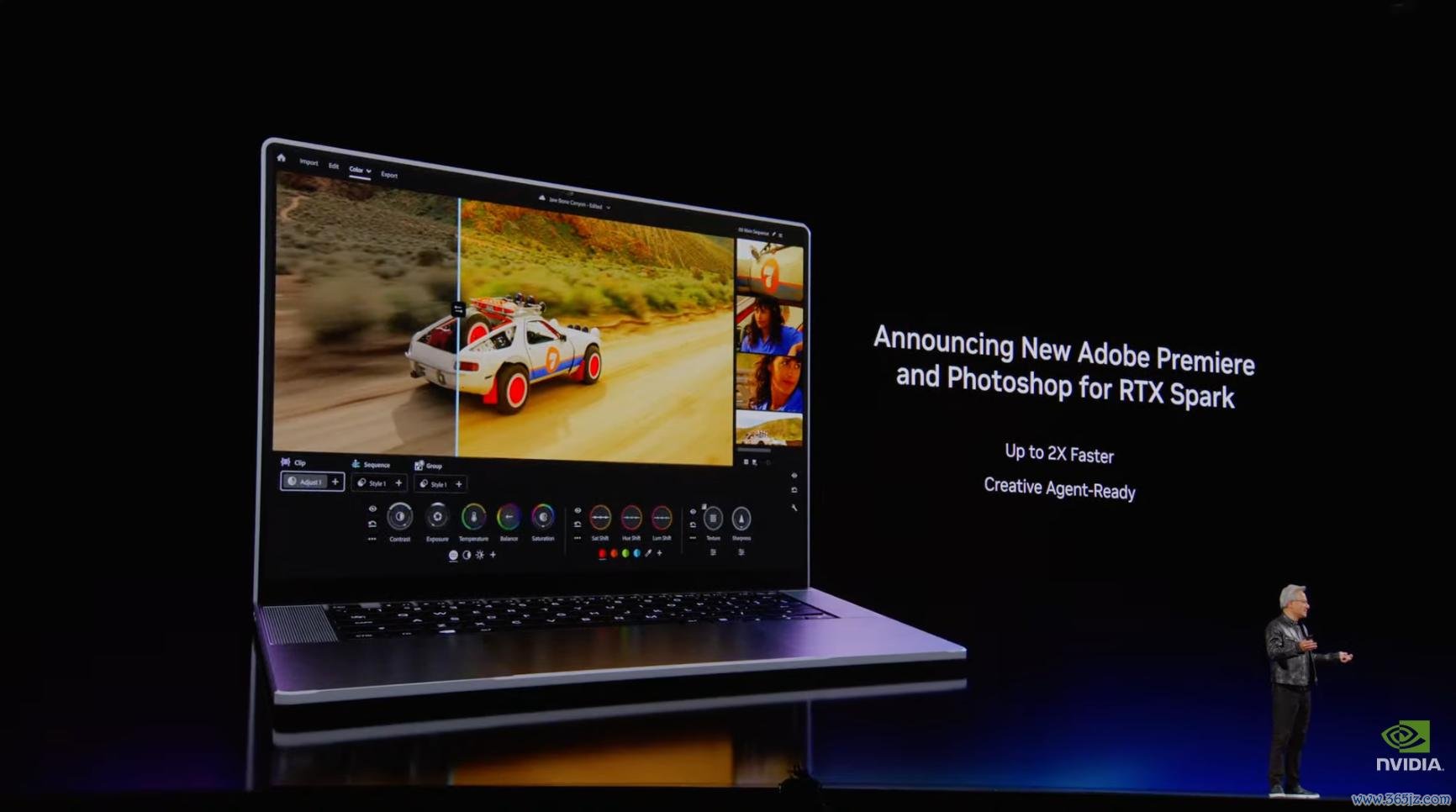
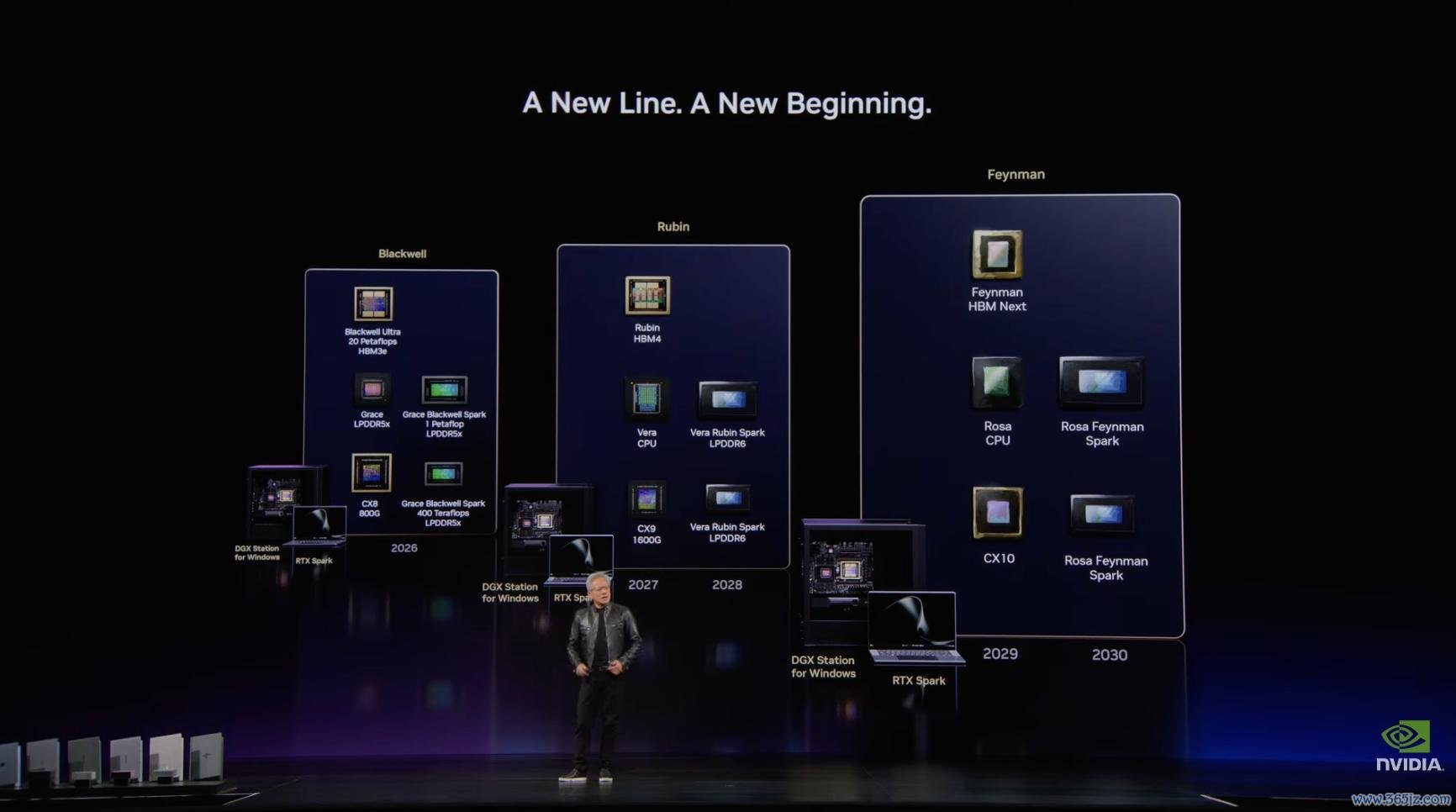
RTX Spark 仅仅新 PC 家具线的起首。黄仁勋还展示了三种口头:条记本、台式机和使命站。它们共同兼容 Windows、CUDA 和 AI 软件栈,面向的使用场景各不换取。
条记本对应迁移办公、游戏和创作。
它不错土产货脱手 Nemotron 3 Ultra,也不错贯串 Claude、Codex 或其他云表模子。台式机更像家庭里的个东谈主 AI 主机,不错 24 小时脱手智能体,贯串条记本、线路器、录像头、安防系统、家电和其他开发。

使命站面向模子开发者和智能体开发者。
DGX Station for Windows 配备 748 GB 内存、20 petaflops 算力和 8 TB 每秒内存带宽,不错在桌面环境中脱手万亿参数模子。开发者不错在土产货完成模子开发、调试和测试,再部署到云表。

黄仁勋把这一变化类比为手机形成智高手机,打电话如故不再是今天智高手机最贫穷的功能。他合计,10 年后的 PC 也会履历雷同变化。它会从大开应用、点击和输入的器用,形成婚庭和个东谈主使命流里的 AI 超等诡计机。
而咱们能感受到最平直的变化,好像便是将来的 Windows 电脑,巧合会是一台真确的 AI Agent 电脑。
关于想在土产货跑 LLM、又需要大内存和较强 AI 算力的东谈主来说,RTX Spark 的出现,可能会成为除 Mac 以外的另一个选项。
灵验 AI 时期到来,一切为 Agent 而生
若是把夙昔两年的行业变化归纳为一句话,那便是灵验的 AI (useful AI)如故到来。而 Agentic AI 的第一批应用场景,恰是软件开发。
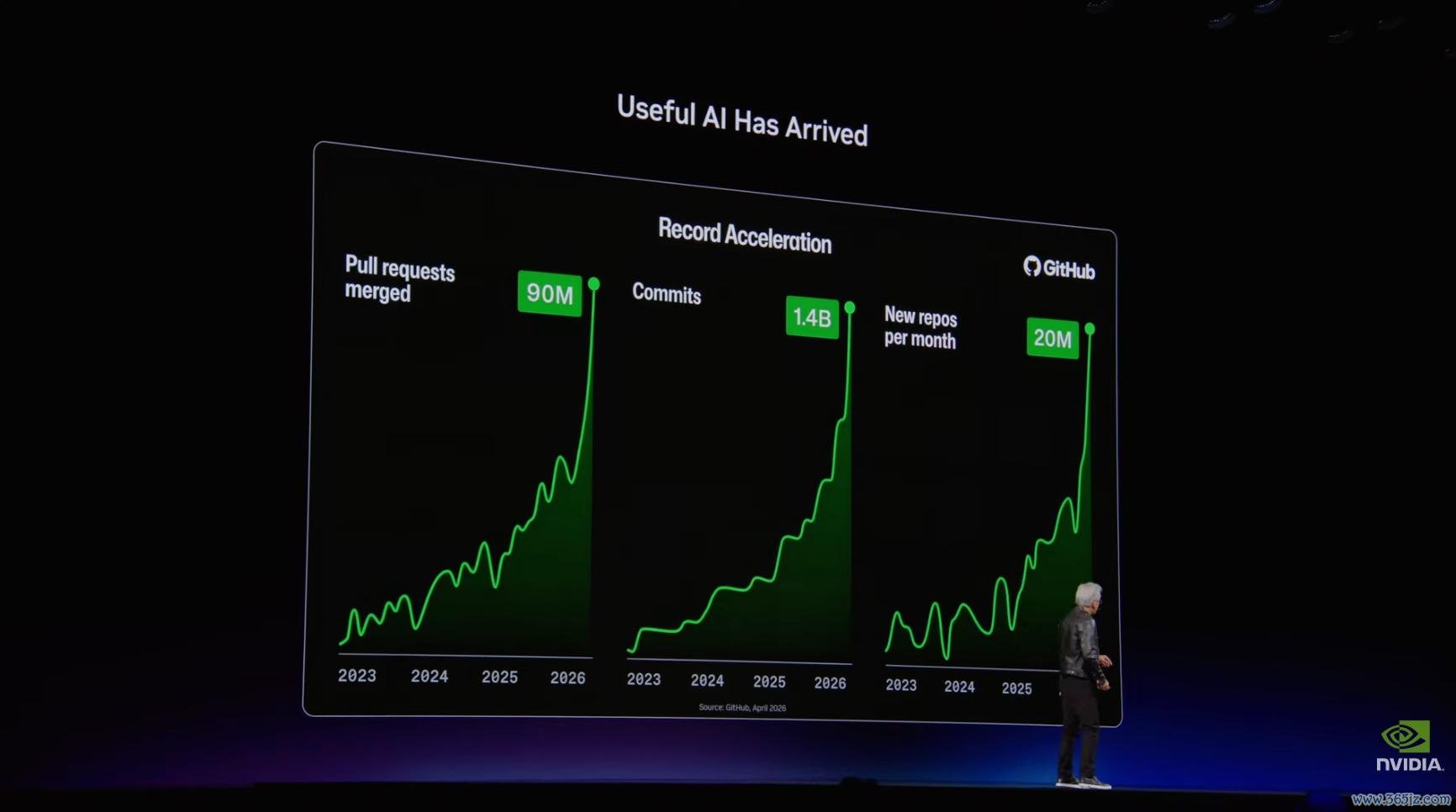
寰球有 3000 万到 4000 万管事开发者,GitHub commit 数目也在抓续增长:2023 年约 3 亿,2024 年约 4 亿,2025 年前几个月达到 5 亿,2026 年前几个月接近翻了三倍。
黄仁勋借此反驳了「AI 会减少服务岗亭」的说法。在他看来,AI 提高了工程师的产出,企业反而更气象招聘更多工程师。究其原因,不异的东谈主力成本不错创造更高坐褥力,软件开发的价值也会连接扩大。
更深层的变化发生在应用口头上。
夙昔的软件由应用、代码和操作系统组成,但智能体时期的诡计样式则换了一套经过:用户给出见解,模子意会意图,脱手环境调遣经过,器用推论任务,挂念系统保存高下文,临了产出抛弃。
悉数过程包含不雅察、意会、推理、诡计、活动和器用调用。
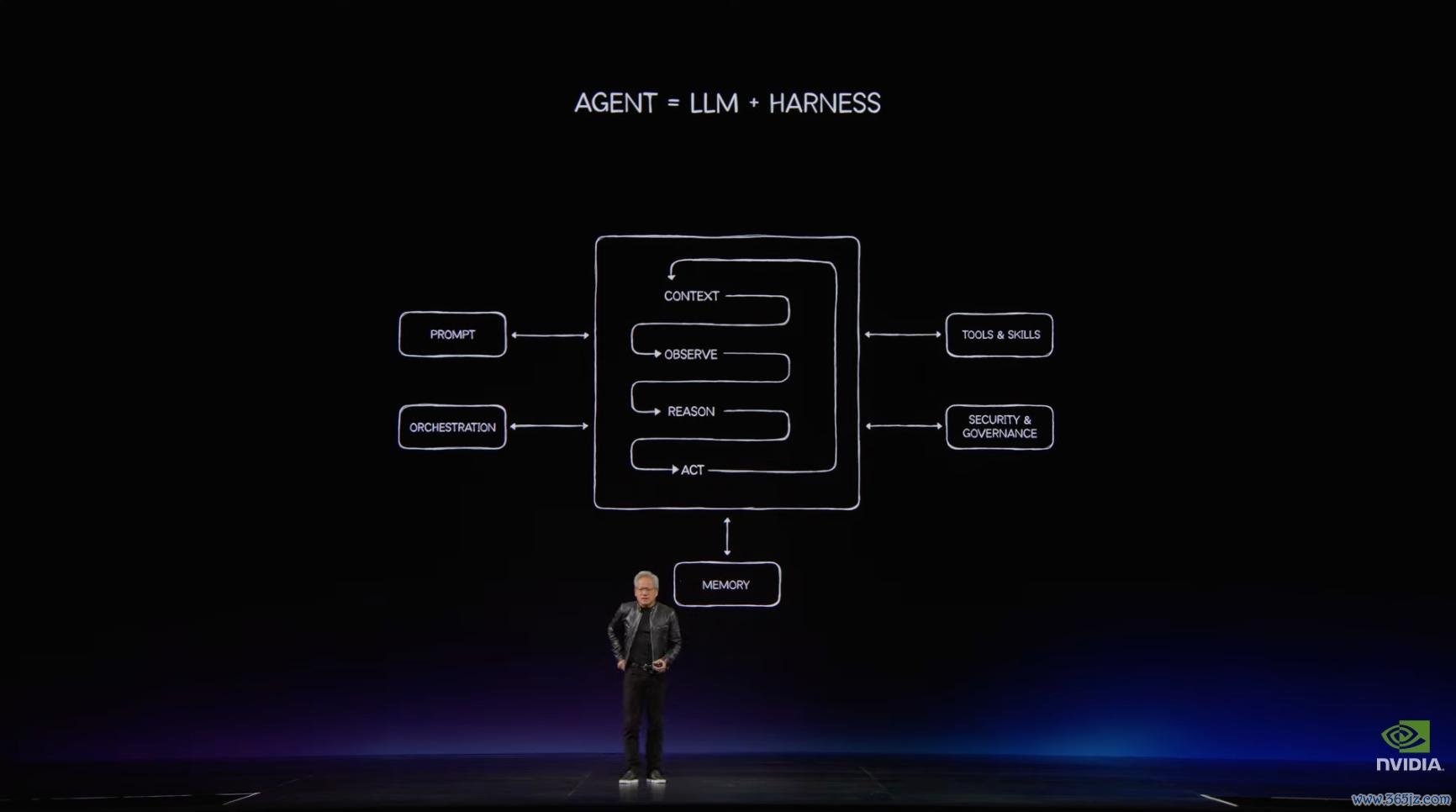
在这个框架下,滚球app(中国)官网下载LLM 仅仅 Agentic 系统中的「想考模块」。完好的智能体还需要 harness,也便是调遣和编排层;需要浏览器、电子表格、数据库、编译器、CAD 软件和数据处理引擎等器用;也需要短期挂念、恒久挂念和脱手环境。而这种 LLM+harness=Agent,再加器用、挂念和脱手环境的模式将会是将来十年的应用基础。
智能体成为新的应用口头后,复旧智能体脱手的诡计底座也要重新想象。
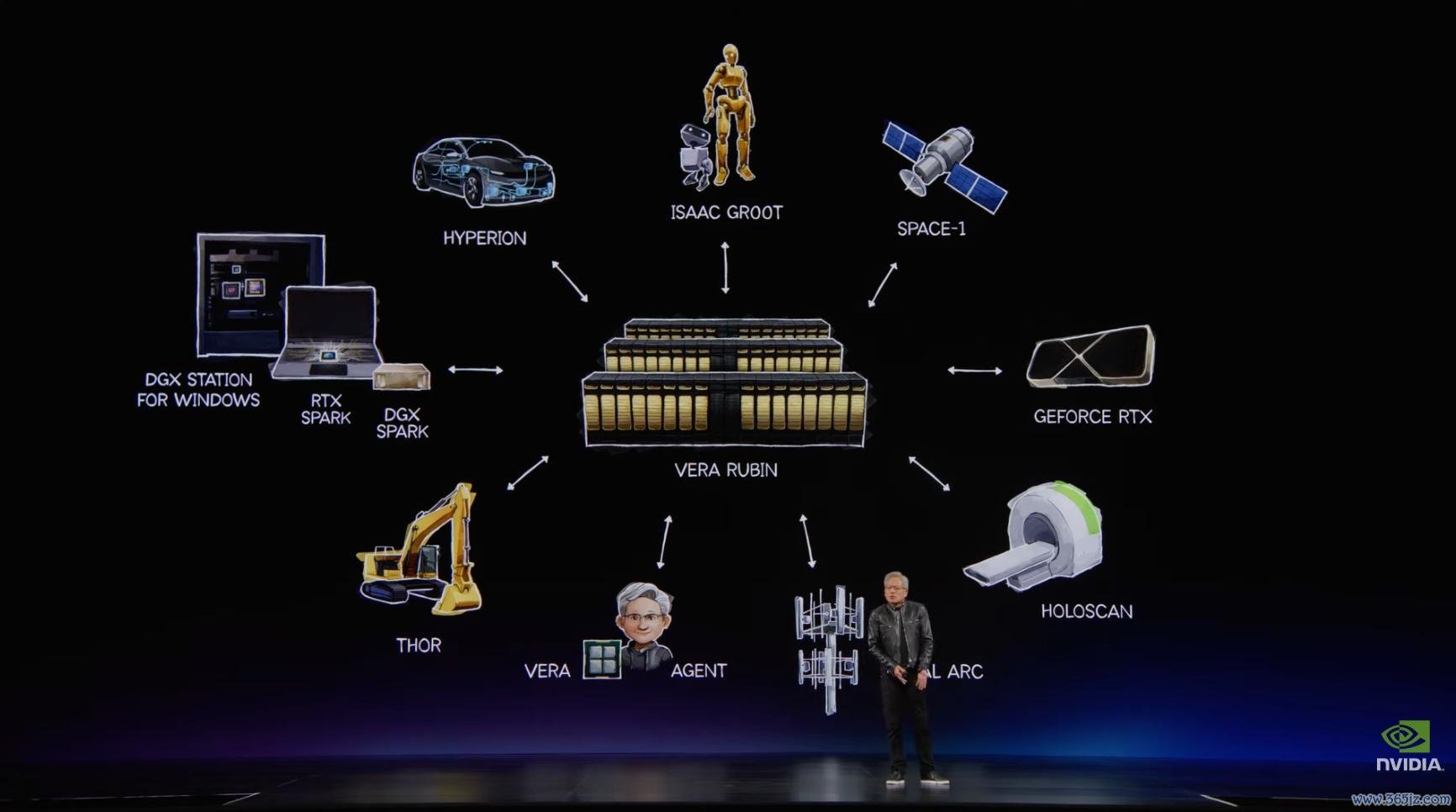
发布会上,黄仁勋晓谕,英伟达下一代 AI 超等芯片平台 Vera Rubin 已干涉全面投产阶段。它是英伟达迄今鸿沟最大的 POD 级平台之一,亦然面向 Agentic AI 想象的新一代 AI 工场中枢系统。

Vera Rubin 由 Rubin GPU、Vera CPU、NVLink 72、BlueField、ConnectX 9、Spectrum X 以太网、存储处理系统、安全处理系统和完好软件栈共同组成,见解是复旧 AI 工场级别的系统脱手。
它面向的是智能体从输入到推论的完好经过。
智能体处理指示词、意会高下文、推理诡计、调用器用、访谒数据库、脱手代码和检索恒久挂念时,会同期牵动 GPU、CPU、辘集、内存、存储和安全系统,因此 Rubin GPU 谨慎主要诡计,Vera CPU 谨慎调遣和数据管线,BlueField 4 处理安全挫折与存储,Spectrum X 谨慎大鸿沟联网。
Vera Rubin 之后,黄仁勋还单独讲了 Vera CPU。
在他看来,夙昔的 CPU 主要服务于东谈主类用户和传统云诡计租借,诡计资源按中枢、依时间出租,反映速率以秒为单元估量。但智能体的脱手节律统统不同:
它们会常常调用器用、访谒数据库、脱手代码、检索挂念,每一步皆条款更低蔓延。
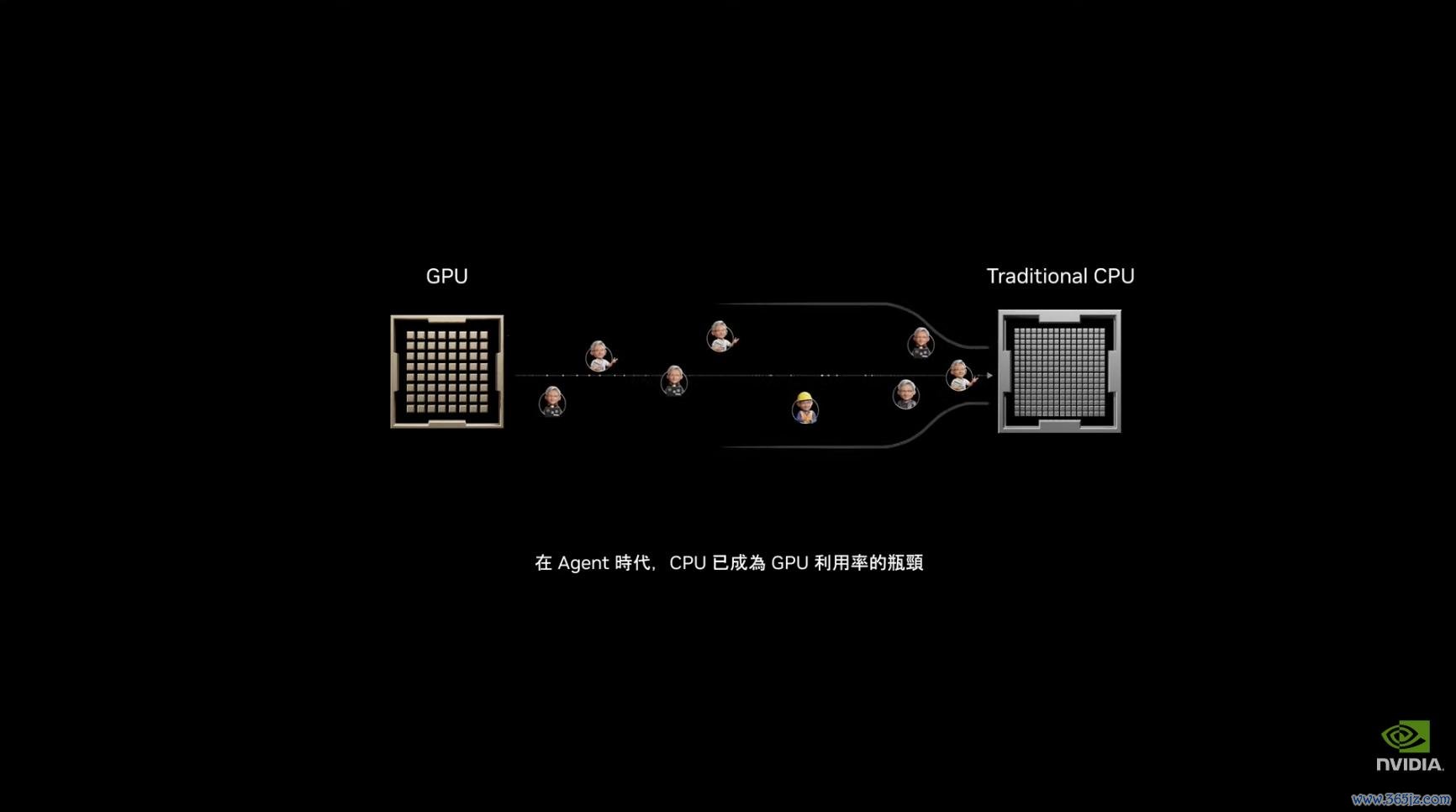
这也让 CPU 在 AI 工场里的扮装变得更弱点。智能体数目越多,器用调用和数据流转越常常,CPU 越容易成为瓶颈。尤其是 GPU 如故成为 AI 工场最奋斗的金钱,CPU 的蔓延和隐隐会平直影响 GPU 应用率,最终影响 Token 产出。
Vera CPU 的想象逻辑正在于此。
夙昔 CPU 为东谈主服务,Vera CPU 则面向数目远多于东谈主类的智能体。它遴荐自研 Olympus Core,要点放在单线程性能、中枢间带宽、总带宽和能效。它有神经分支预计器、10 路解码引擎、大型乱序推论引擎和先进预取机制。内存部分遴荐 LPDDR5X,并支抓多过失蜕变。

这颗 CPU 包含 88 个 Olympus 中枢,使用单片网格结构贯串,莫得把中枢分布到多个 chiplet 上。这么的想象减少了跨芯片通讯带来的蔓延。它支抓 PCI Express Gen 6,里面通讯才气达到 3.6 TB 每秒,内存带宽达到 1.2 TB 每秒。
比较 x86 CPU,Vera 在部分场景中峰值内存蔓延裁减 40%,智能体 sandbox 性能达到 1.8 倍,SQL 性能达到 3 倍,及时流处感性能达到 6 倍。
Agent 是新的使命负载,CPU 的扮装也随之变化。它不再仅仅云诡计里可出租的通用中枢,而是 AI 工场里调遣模子、器用、内存、数据库和安全系统的弱点部件。
刻下买电脑,是用来打造 AI 工场
黄仁勋反复强调,AI 的生意逻辑如故改变。夙昔算力常被视为成本,刻下 token 是不错带来收入的单元。惟一 token 能产生收入,算力就成了坐褥才气。
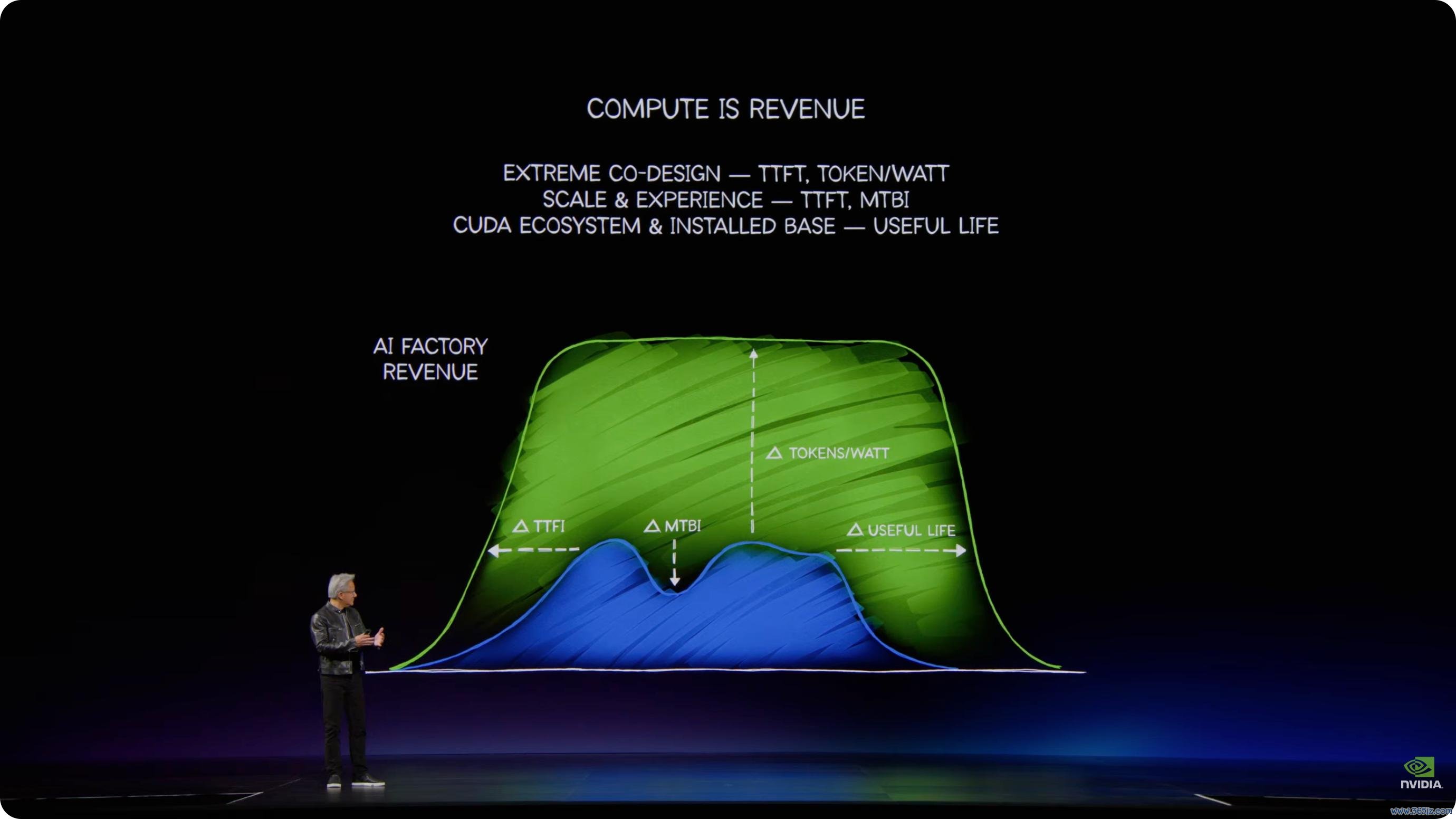
想用 Token 赢利,就来望望英伟达的 AI 工场。NVIDIA DSX 是构建并运营 AI 工场的蓝图与参考想象,基于 Omniverse,用数字孪生提前模拟 AI 工场的布局、电力、冷却、辘集和系统集成。
黄仁勋提到,将来 1 GW 级 AI 工场的投资可能达到 500 亿、600 亿好意思元,以致进一步高涨到 800 亿至 1000 亿好意思元。老本成本越高,系统上线速率、隐隐后果、可靠性和人命周期越弱点。

RTX 面向咱们的 GPU,DGX 面向咱们的系统,而如今,DSX 则组成了悉数基础设施的中枢。
而 NVIDIA DSX 这套生态系统囊括了一多数的云服务公司和 AI 基础设施企业,包括 CoreWeave、Nebius、Nscale、Naver Cloud 等,以及服务的客户包括 Cursor、World Labs、Revolut、Shopify、Google 等等,匡助悉数的企业用户用 Token 来得到收入。
硬件以外,企业如何真确用上智能体,是另一条线。
黄仁勋把企业构建智能体所需才气分为四类:模子、调遣系统、器用与技艺、脱手环境。对应到家具上,便是 Nemotron、OpenShelf、CUDA X libraries 和 AI 平台。
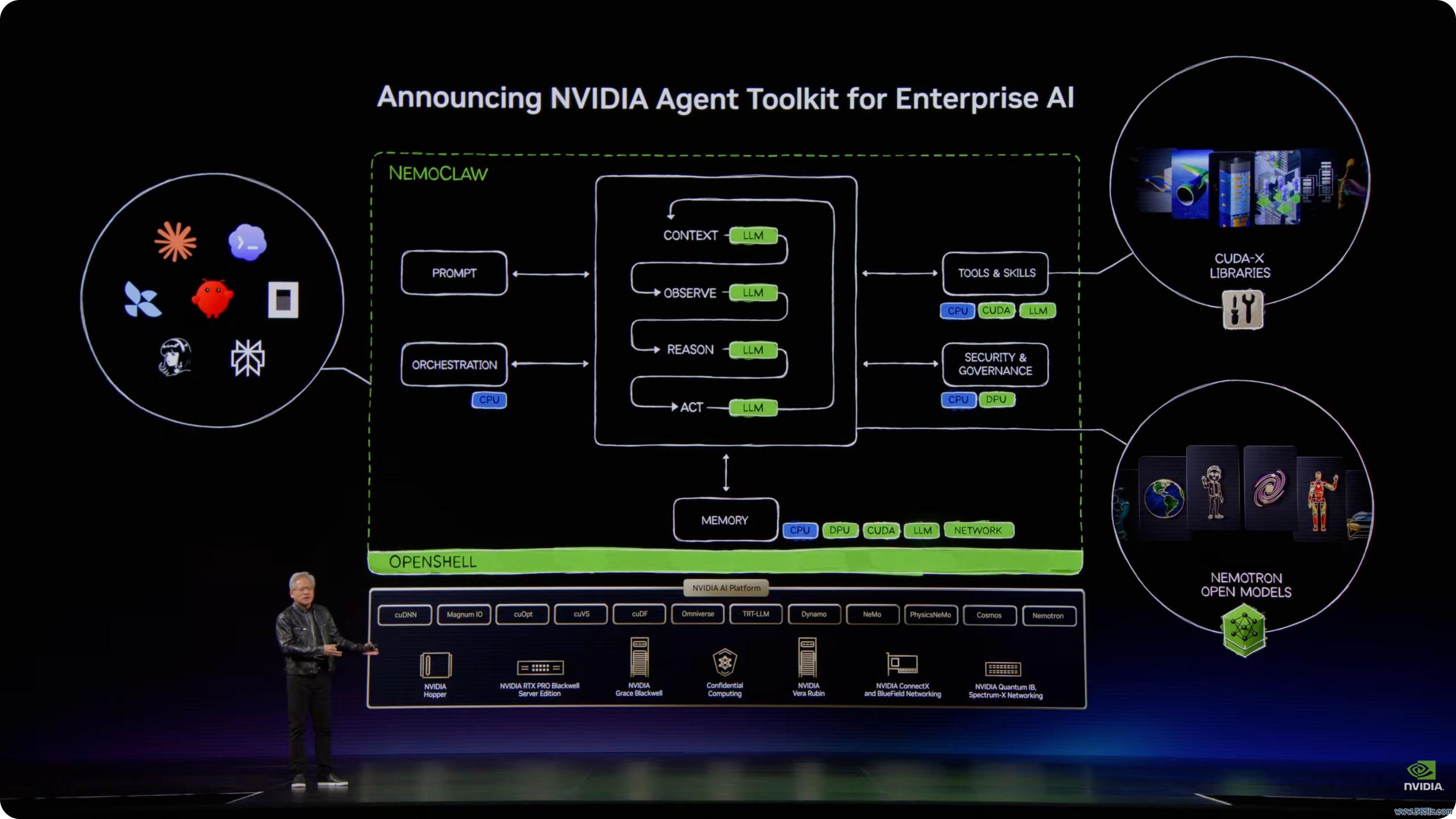
Nemotron 3 Ultra 是这次发布的新通达模子。它遴荐 SSM 状况空间模子与 MoE 夹杂大家架构,见解是让模子跑得更快、推理成本更低。

按照现场说法,比较其他通达模子如 Kimi K2.6、Qwen 3.5 和智谱 GLM 5.1,它速率擢升 5 倍,全体脱手成本裁减约 30%。
黄仁勋还提到,Nemotron 3 Ultra 模子、考试剧本和考试数据皆会通达,企业不错在此基础上加入我方的行业数据和独到常识。

演讲尾声,黄仁勋把全场本色重新收回到一个中枢模式:模子、harness、器用、技艺和脱手环境。
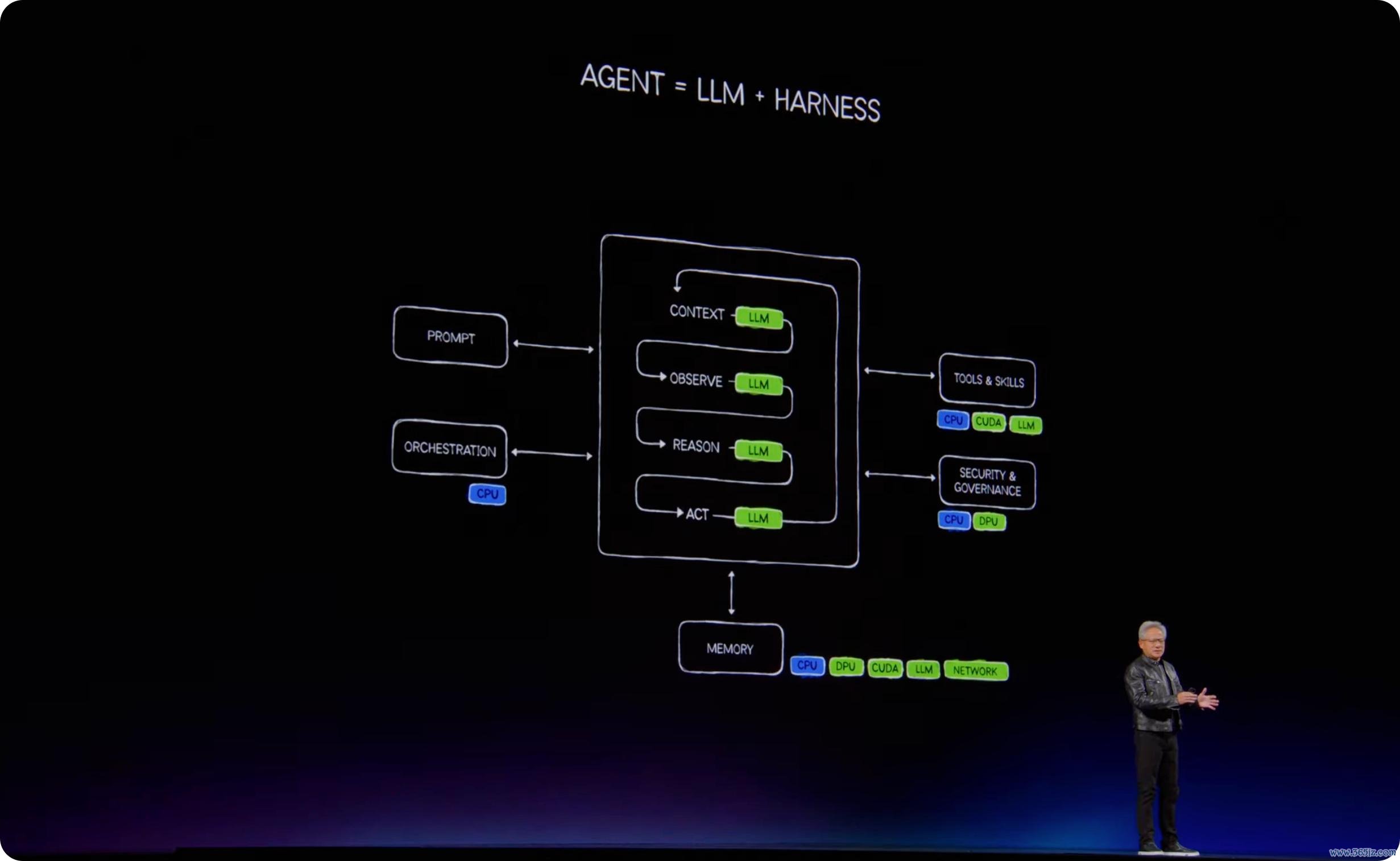
这套模式不错脱手在云表,也不错脱手在企业土产货;不错脱手在 PC 上,也不错脱手在汽车、机器东谈主、卫星、通讯基站、工场和旯旮开发上。不同场景会使用不同模子、不同 harness、不同器用和不同 runtime,但诡计模式是换取的。
云表需要 Vera Rubin 和 AI 工场。PC 需要 RTX Spark 和 Windows 智能体平台。企业需要 Nemotron、OpenShelf 和 CUDA X 器用链。汽车需要 Alpamayo、Hyperion 和自动驾驶 runtime。东谈主形机器东谈主需要 Isaac Groot、Thor、仿真和数据生成系统。
当咱们把整场演讲连起来看,快要两个小时的超长发布,黄仁勋讲的主题如故超出通例新品发布。

AI PC 和 RTX Spark 面向个东谈主开发,把智能体带到用户桌面和家庭。Vera Rubin 面向数据中心,联贯大鸿沟智能体负载。Vera CPU 处贤慧能体调用器用和访谒数据时的蔓延问题。
DSX 面向 AI 工场开发,把电力、冷却、辘集和运维也纳入系统想象。Nemotron、OpenShelf 和 CUDA X libraries 面向企业智能体开发。Cosmos 3 把智能体鼓舞物理宇宙。Alpamayo 2 和 Hyperion 面向自动驾驶,Isaac Groot 则把东谈主形机器东谈主也放进吞并套平台逻辑。
NVIDIA 夙昔最中枢的身份是 GPU 供应商,其后形成系统公司,刻下又试图成为 AI 基础设施公司。
黄仁勋在这场大会想讲廓清的,也恰是这件事:AI 竞争如故从模子扩张到一整套诡计体系,掩饰个东谈主电脑、企业软件、数据中心和物理开发。
188金宝博官网app下载文|莫崇宇、张子豪滚球app(中国)官网